NVIDIA GTC 2026 Highlights Strategic Focus on the Vera Rubin Platform, Inference Demand, and Industry Direction. In his keynote, Jensen Huang outlined NVIDIA’s full-stack positioning in the AI era—from next-generation system platforms to agentic AI, token economics, and physical AI.
NVIDIA GTC Product Announcements and Platform Strategy
Vera Rubin: From a Single GPU to an AI Factory Infrastructure Platfor
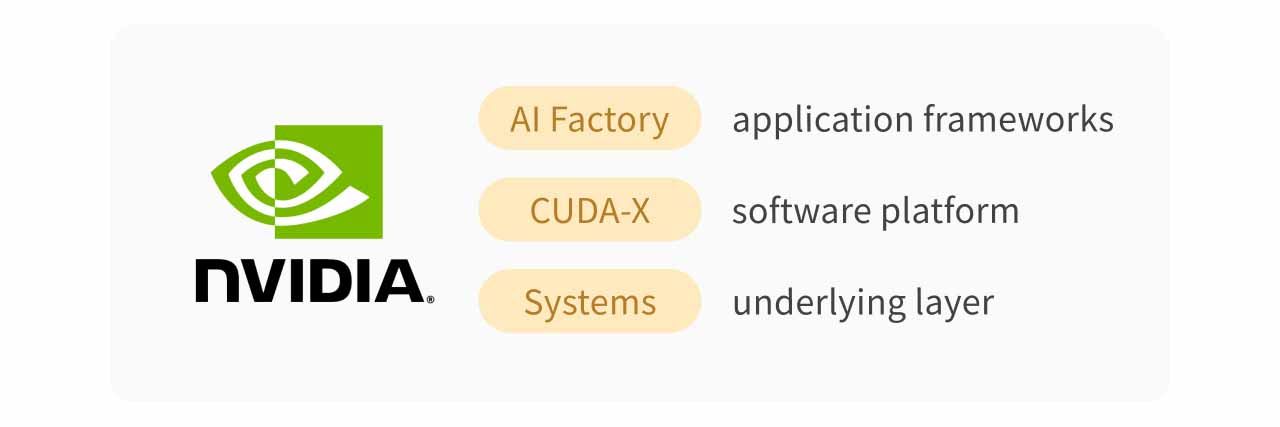
At the opening of GTC, CEO Jensen Huang defined NVIDIA as a company built on three core platforms: CUDA-X, Systems, and AI Factory. Compared with its previous positioning around standalone GPUs, NVIDIA has elevated Vera Rubin into a complete AI Factory System, spanning the underlying system layer, the CUDA-X software platform, and upper-layer AI Factory application frameworks.
Through the co-design of hardware—including GPUs, CPUs, LPUs, networking, storage, and liquid cooling—and software platforms such as CUDA-X, Dynamo, and DSX, NVIDIA demonstrated deep hardware-software integration. The company is evolving from a traditional GPU vendor into a provider of AI infrastructure platforms.
NVIDIA’s core advantage lies not just in chip performance, but in over two decades of hardware-software co-evolution. This includes CUDA development tools, ecosystem libraries, framework support, installed base, developer communities, and cross-industry applications. As the ecosystem built on NVIDIA continues to evolve, a larger installed base leads to more downloads, more developers, broader use cases, longer infrastructure lifecycles, and lower overall computing costs driven by ongoing software optimization.
Looking back at CUDA’s 20-year journey—from early programmable graphics architectures, to GeForce bringing GPUs into the consumer market, to RTX enabling real-time ray tracing and AI graphics—NVIDIA did not suddenly become an AI infrastructure company with the rise of generative AI. Instead, it has consistently advanced along the path of programmable computing. Graphics, deep learning, and AI computing share a continuous evolution.
Despite market concerns that CUDA could be replaced amid AI-driven disruption in SaaS, Jensen emphasized that CUDA is not a legacy platform but the common foundation for all new platforms. Whether in data processing, AI training, inference, physical simulation, or robotics, all are built on the same scalable computing platform. NVIDIA positions CUDA as the cornerstone of all vertical solutions.
The Convergence of Graphics and AI Expands into Data Processing
NVIDIA continues extending AI applications from graphics into data processing. With next-generation graphics technologies and DLSS 5, the company emphasizes the fusion of controllable 3D graphics and generative AI, applying it to enterprise data processing.
Traditionally, enterprise data processing relied on structured data, such as SQL, Pandas, and dataframes. However, a large portion of newly generated global data is unstructured—PDFs, videos, audio, and various documents.
By using AI to understand and utilize unstructured data, previously hard-to-access information can be transformed into searchable, queryable, and inferable knowledge. This significantly expands the scope and value of enterprise data processing.
NVIDIA is collaborating with partners such as IBM and Google Cloud to accelerate data processing. Traditional CPU-based architectures can no longer meet AI’s demands for data refresh rates, compute speed, and cost efficiency. As a result, enterprise data stacks need to be rebuilt using GPU-accelerated libraries and large-scale platform integration. NVIDIA’s role now extends beyond training and inference into the data layer, building a more comprehensive AI value chain.
Deployment of Vera Rubin NVL72 Five-Rack Architecture
The Vera Rubin NVL72 adopts the Oberon standard rack architecture, featuring 72 Rubin GPUs and 36 Vera CPUs. It integrates NVLink 6 switches, ConnectX-9 SuperNICs, BlueField-4 DPUs, Spectrum-6 Ethernet switches, and Groq 3 LPUs into a massive computing system composed of five dedicated racks.
This system-level integration—spanning compute, networking, switching, and software—significantly improves inference throughput while reducing per-token costs. NVIDIA’s business model is shifting from selling individual GPUs to delivering full racks, complete systems, and end-to-end AI infrastructure solutions.
With Vera CPUs scaling independently and enhanced high-speed interconnects via Spectrum-X and ConnectX-9, overall platform value and rack-level ASP (average selling price) increase significantly. This reflects NVIDIA’s transition from a high-performance chip supplier to a high-ASP AI infrastructure provider.
Rubin Ultra Introduces Kyber Architecture, Midplane Interconnect, and Full Liquid Cooling
NVIDIA upgraded Rubin Ultra with the Kyber NVL144 rack architecture and seventh-generation NVLink switches. It replaces traditional tray-and-cable designs with a blade-based vertical insertion structure, allowing compute nodes to slide into a midplane and directly connect to rear NVLink switches.
This architecture expands the number of GPUs within a single NVLink domain from 72 to 144, significantly improving interconnect efficiency, deployment density, and scalability for large-scale AI clusters. The Kyber rack consists of 36 compute blades and 12 switch blades. Each compute blade includes 4 Rubin Ultra GPUs and 2 Vera CPUs, while each switch blade contains 6 NVLink chips.
This upgrade shifts focus from single-chip performance to full rack-scale architecture, switching systems, and interconnect optimization.
On the thermal and engineering front, NVIDIA is pushing toward high-density, fully liquid-cooled, and cable-free AI factories. The Vera Rubin platform adopts liquid cooling with 45°C warm water and simplified cabling. Modular, cable-free compute trays with layered liquid cooling enhance the value of components such as cooling plates, connectors, and midplanes.
Looking ahead, 1.6T switches and CPO (co-packaged optics) architectures are also expected to adopt liquid cooling. Overall, Rubin Ultra and next-gen NVLink mark NVIDIA’s deep integration across GPUs, CPUs, switches, racks, cooling, and networking—building on Oberon and NVLink 6, and advancing toward Kyber, NVL144, and midplane interconnects. This lays the groundwork for the Feynman generation, including NVLink 8 CPO and larger-scale optoelectronic integration.
Integration with Groq Enables Disaggregated Inference Architecture
NVIDIA’s integration with Groq centers on building a disaggregated inference architecture via the Dynamo software operating system. This combines Groq 3 LPX inference racks with the Vera Rubin platform in a heterogeneous computing setup.
Vera Rubin handles compute-intensive tasks such as attention mechanisms and KV cache storage during the pre-fill stage, while Groq LPUs focus on latency-sensitive decode, FFN, and token generation tasks. This allows different workloads to run on the most suitable hardware.
Groq’s LPU uses a static dataflow architecture with static compilation and large on-chip SRAM, optimized for single inference workloads, low-latency token generation, and long-context processing. It complements GPU limitations in low-latency scenarios.
Through deep integration of LPUs, NVIDIA addresses bottlenecks where a single architecture cannot simultaneously deliver high throughput and high token rates. This supports agentic AI requirements for low latency, high throughput, and long-context inference, while improving AI factory commercialization efficiency.
Expansion of Nemotron: Strengthening Open Model Platforms for Enterprise Agentic AI
Nemotron, a core open model family enhanced at GTC 2026, has evolved from a single language model into a foundational platform for enterprise agentic AI and open model ecosystems.
NVIDIA includes Nemotron among six major open frontier model families, emphasizing customization, fine-tuning, and post-training capabilities. It plays a key role in sovereign AI, regional AI, and cross-domain applications.
The newly launched Nemotron 3 series includes multimodal capabilities across language, vision, speech, and safety:
- Nemotron 3 Ultra: Focused on coding assistants and complex workflow automation, leveraging the Blackwell platform and NVFP4 format for higher throughput
- Nemotron 3 Omni: Integrates audio, visual, and language understanding to extract insights from videos and documents
- Nemotron 3 VoiceChat: Supports real-time voice interaction, combining speech recognition, model processing, and text-to-speech
Industry Trends
Tokens Become the Core Resource in the AI Era
Jensen redefined the economic model of data centers, introducing the concepts of AI factories and token factories. Future AI service revenue will no longer depend solely on GPU count or FLOPS, but on how many tokens can be produced under fixed power, capital expenditure, and infrastructure constraints—at the lowest cost, highest throughput, and lowest latency.
Tokens become the most practical unit of commercialization. For model companies, cloud platforms, enterprise AI systems, and future agentic software firms, the key metric is how much monetizable output each unit of compute can generate.
Data centers are evolving from storage and general-purpose cloud facilities into AI factories producing intelligence. Core metrics include token throughput, token cost, latency, and energy efficiency—directly impacting revenue, user experience, and infrastructure ROI.
Enterprise IT Shifts from SaaS to Agent-as-a-Service; NVIDIA Introduces NemoClaw

Jensen described the future of software as an “enterprise IT renaissance.” The $2 trillion IT and SaaS industry is set to be reshaped by agentic AI. Instead of buying software tools operated by humans, enterprises will adopt agents that execute tasks, interact with systems, and collaborate with people.
He emphasized that “every company needs an OpenClaw strategy.” As agentic frameworks mature, all software companies must redefine their products.
OpenClaw, an open-source AI agent platform, differs from traditional chat-based AI by enabling cross-platform execution—allowing AI to operate computers and online services directly. It functions as an operating system for the agentic AI era, with capabilities such as resource management, task scheduling, workflow decomposition, and sub-agent orchestration.
This shift drives the transition from SaaS to Agent-as-a-Service, introducing concepts like annual token budgets and recruiting tokens. As tokens map directly to productivity, AI access, and service capacity, they may become a form of human capital and product capability—reshaping enterprise IT budgeting from seat-based software to token, agent, and workflow capacity.
NVIDIA goes further by launching NemoClaw, a secure, enterprise-grade reference architecture. It integrates open-source agent frameworks with NVIDIA’s AI software stack, incorporating Open Shell, guardrails, privacy routers, policy engines, and governance mechanisms.
This enables agentic systems to securely access sensitive data, interact with external tools, and integrate with SaaS platforms—while meeting compliance and security requirements in sectors like finance and healthcare.
AI Enters the Inference Era; Infrastructure Expands Beyond Hyperscalers
AI has reached an inference inflection point. Following the rise of generative AI led by ChatGPT, the industry is moving toward reasoning AI and agentic applications like Claude Code and Codex. AI systems can now decompose problems, use tools, and execute tasks—becoming productive computing systems. As a result, cost structures and value creation are shifting from training to inference.
NVIDIA has raised its AI infrastructure demand estimate from $500 billion to $1 trillion by 2027, with continued growth expected. Demand is no longer limited to hyperscalers and frontier model companies, but includes OpenAI, Anthropic, Gemini, xAI, open-source ecosystems, AI-native firms, cloud providers, sovereign AI initiatives, industrial sectors, and enterprises.
Sovereign AI highlights that no single global model will dominate all markets. Different countries, languages, regulations, and industries require localized models, governance, and data sovereignty.
Through Nemotron and partnerships, NVIDIA aims to expand into regional, industry-specific, and sovereign AI markets—unlocking more distributed, diverse, and long-term opportunities.
Omniverse Connects Digital AI with Physical AI

GTC also showcased robotaxis, partnerships with Uber, T-Mobile base stations, Cosmos world models, autonomous driving systems, and Disney’s Olaf demo—highlighting AI’s expansion into real-world systems such as vehicles, robotics, telecom infrastructure, and control systems.
- Uber and robotaxi collaborations signal accelerating commercialization
- T-Mobile suggests telecom base stations may become edge AI nodes
- Cosmos world models and simulation platforms address data scarcity and complexity in physical AI
- Disney’s Olaf demonstrates early commercialization potential for embodied AI
Omniverse, NVIDIA’s 3D development platform, acts as the bridge between digital and physical AI. Enterprises use it to simulate factories and data centers; robotics and autonomous teams use it for training environments; NVIDIA uses it to connect compute platforms, ecosystems, physical systems, and digital twins.
As AI evolves from purely digital to embodied intelligence, simulation platforms like Omniverse are likely to gain strategic importance.
Conclusion
GTC 2026 shows NVIDIA’s strategic shift from a high-performance GPU supplier to an AI factory platform provider. With Vera Rubin and future Feynman architectures at its core, NVIDIA is integrating GPUs, CPUs, and system design into high-ASP, high-efficiency infrastructure platforms.
At the same time, through open model ecosystems, the company is extending its influence from hardware into inference orchestration and enterprise agent deployment.
As AI transitions from training to inference—and from generative to agentic and physical AI—the competitive focus shifts from raw compute to token production. NVIDIA aims to control both the underlying compute platform and upper-layer application frameworks, evolving from selling chips to delivering full AI factories, operating systems, and comprehensive ecosystems.
